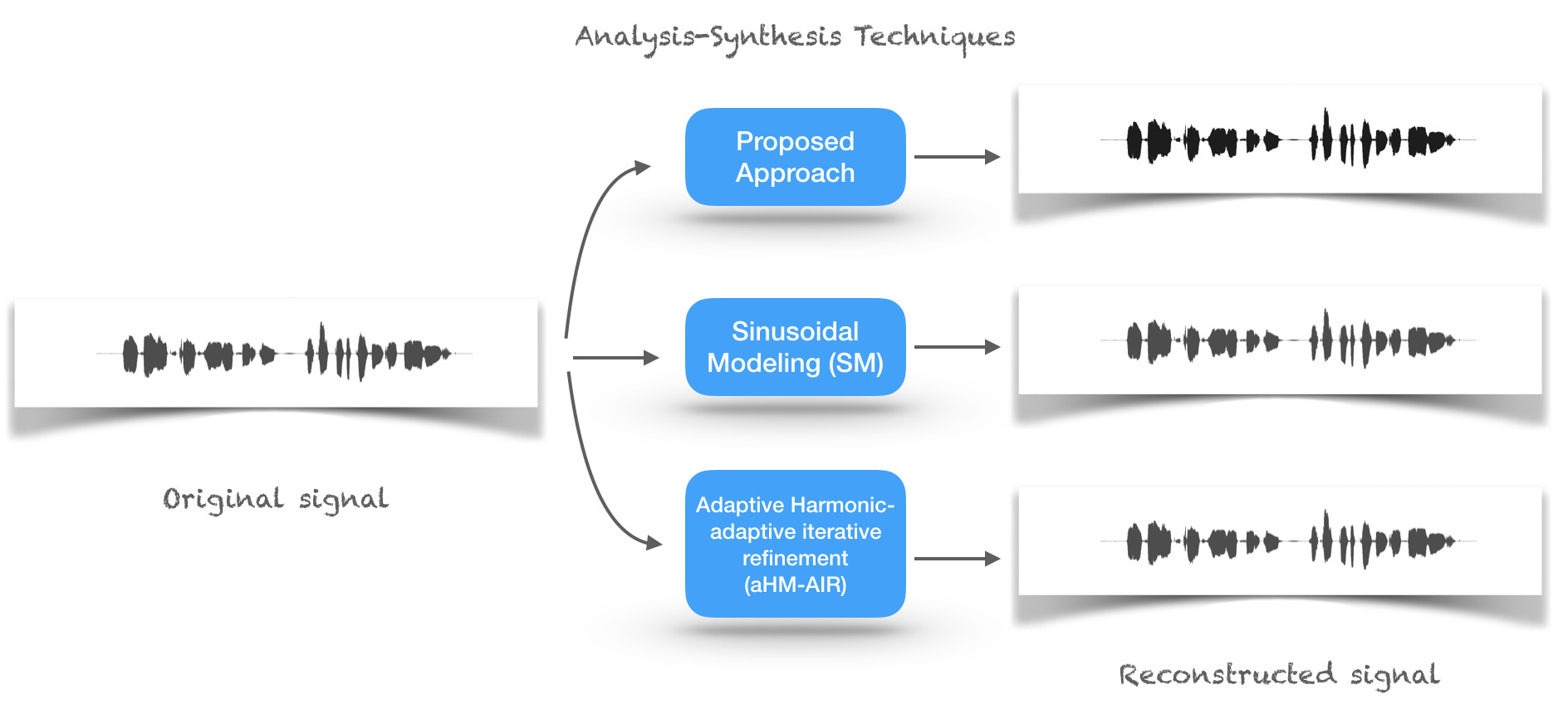
Proposed Approach
Speech signals contain a fairly rich time-evolving spectral content. Accurate analysis of this time-evolving spectrum is an open challenge in signal processing.
Towards this, we designed an approach which overcomes some of the challenges using foundational concepts in signal processing.
The webpage gives a quick pictorial presentation of the idea. Also, we have provided some example speech utterances for you as a listener to judge the quality of the processing.
About the technique: The estimation operates on the whole signal without any short-time analysis.
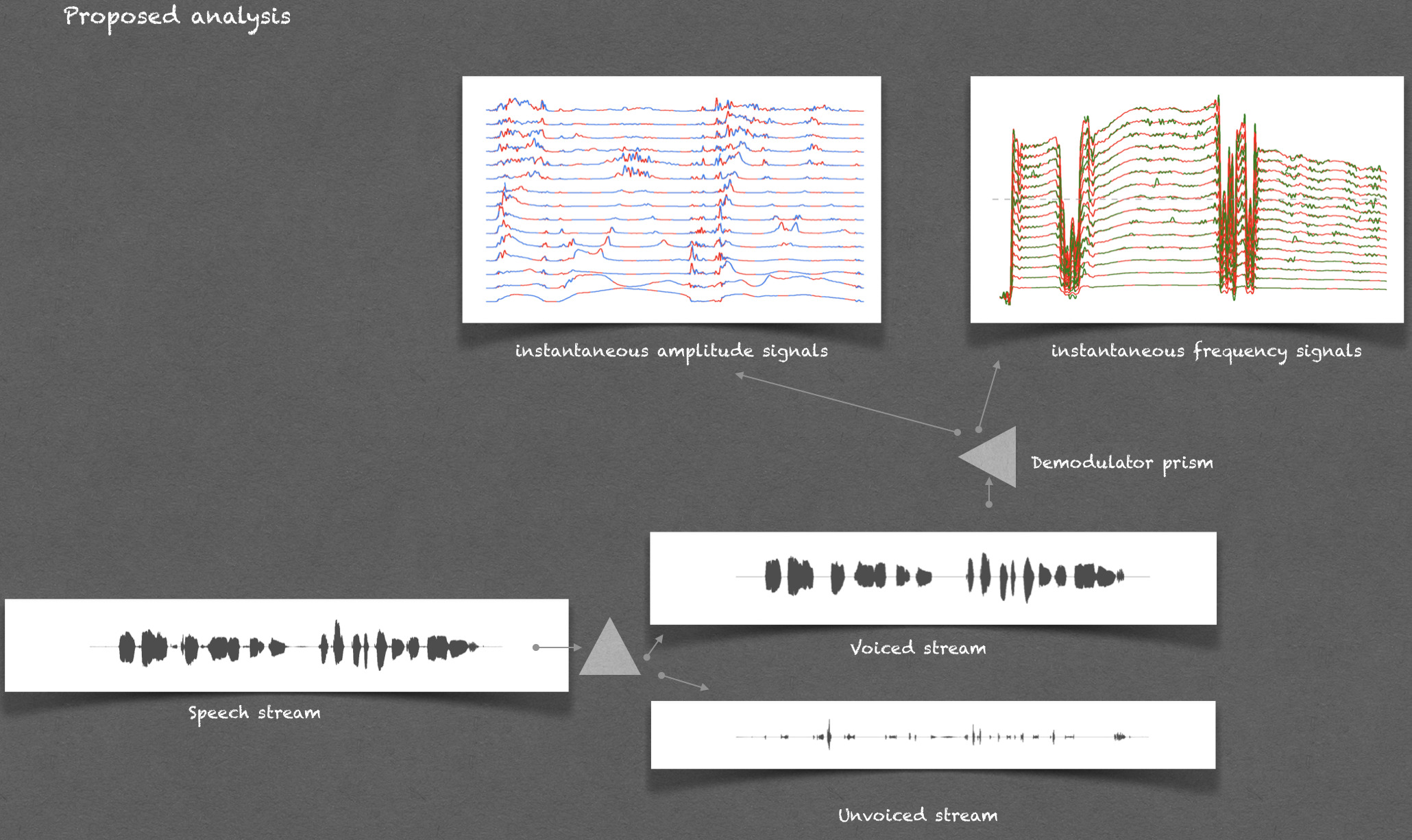
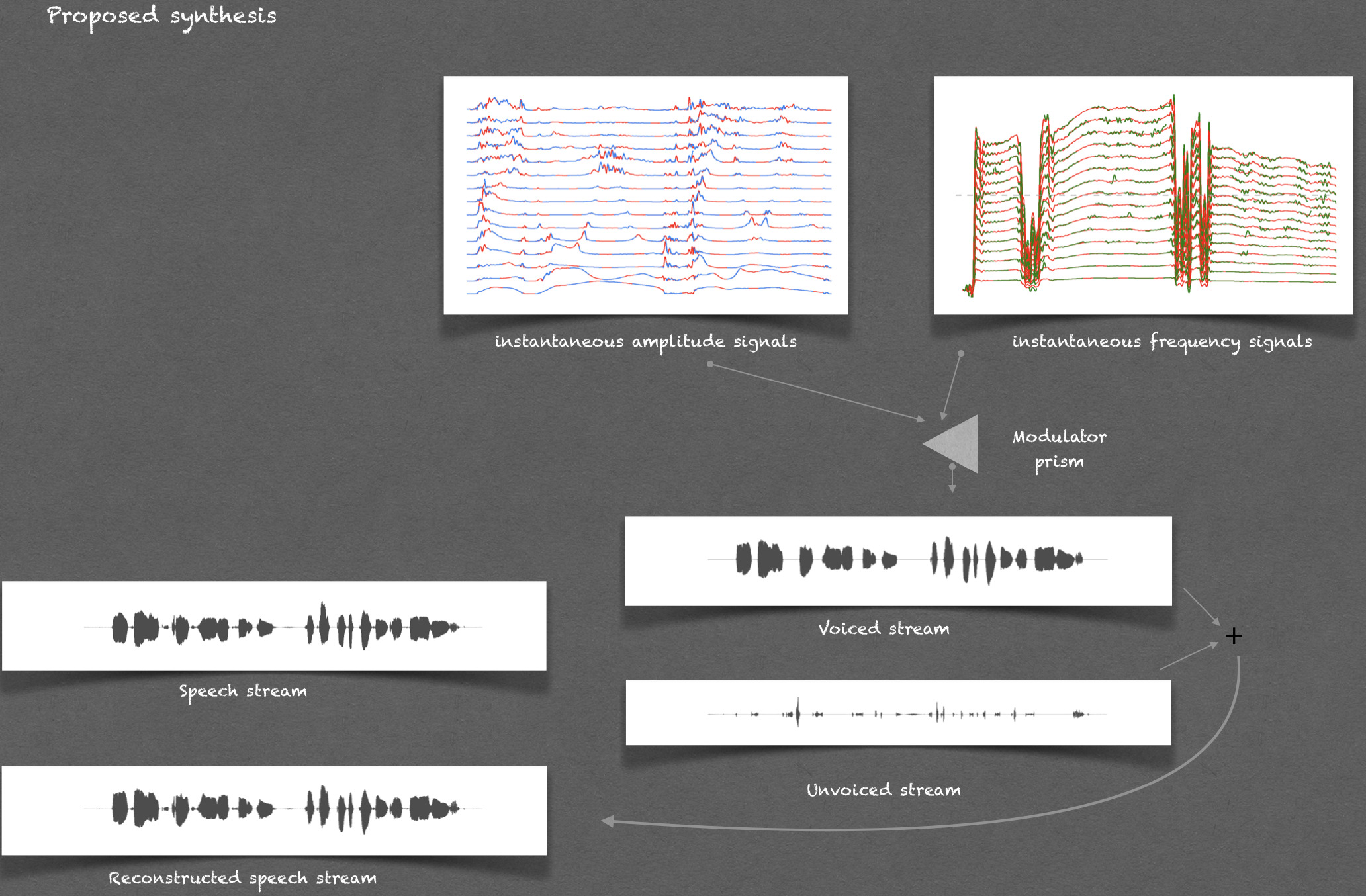
The approach proceeds by extracting the fundamental frequency sinusoid (FFS) from speech signal.
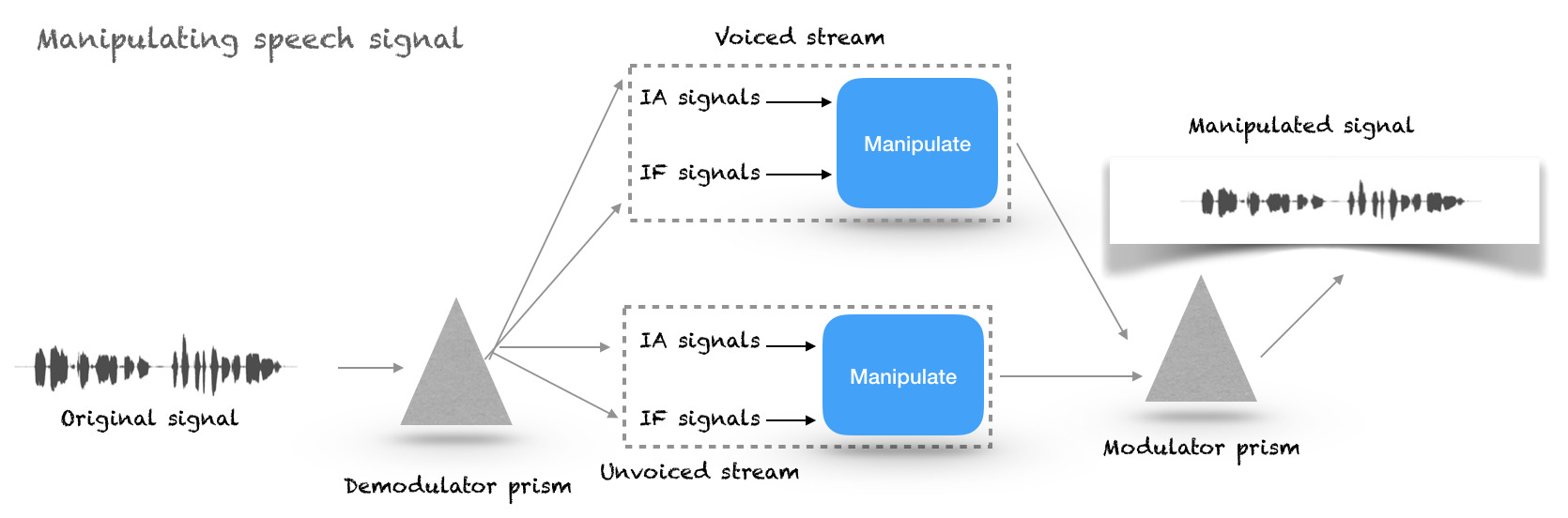
The instantaneous amplitude (IA) of the FFS is used for voiced/unvoiced stream segregation.
The voiced stream is then demodulated using a variant of in-phase and quadrature-phase demodulation carried at harmonics of the FFS.
The result is a non-parametric time-varying sinusoidal representation, specifically,
an additive mixture of quasi-harmonic sinusoids for voiced stream and a wideband mono-component sinusoid for unvoiced stream.
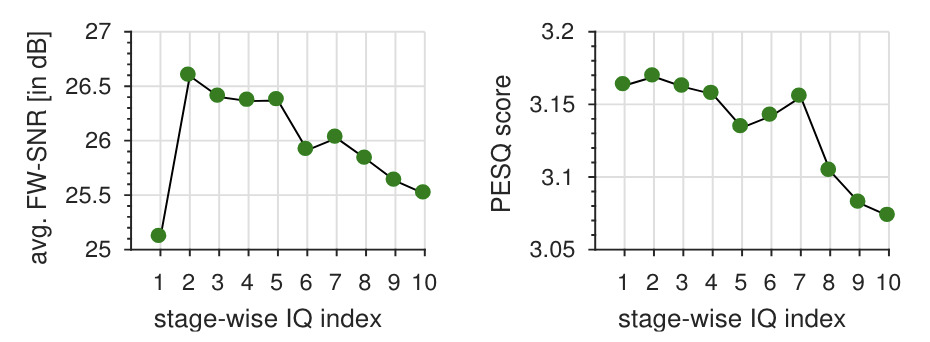
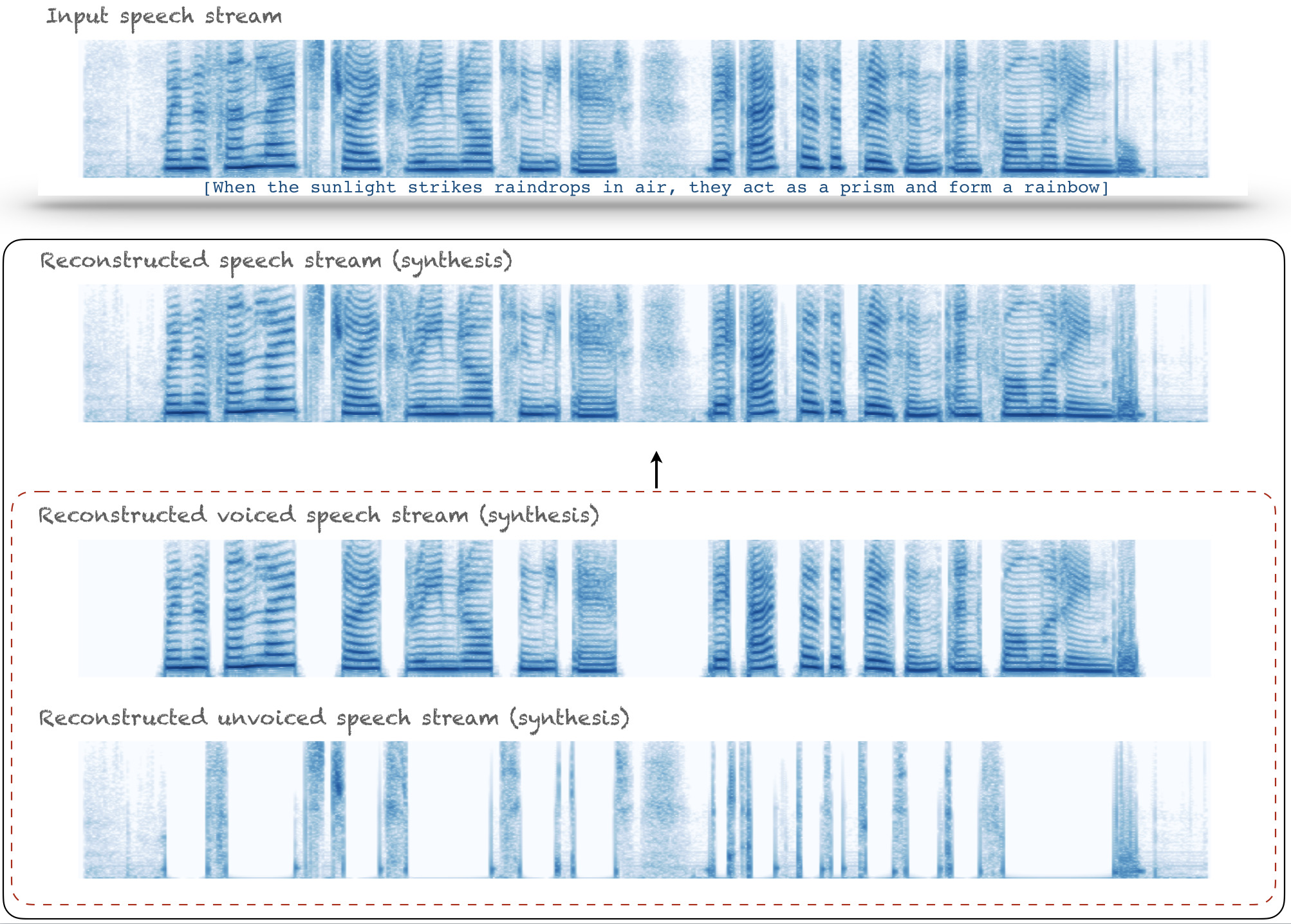
The representation is evaluated for analysis-synthesis, and the bandwidth of IA and IF signals are found to be crucial in preserving the quality. Also, the obtained IA and IF signals are found to be carriers of perceived speech attributes, such as speaker characteristics and intelligibility.
On comparing the proposed modeling framework with the existing approaches, which operate on short-time segments, improvement is found in simplicity of implementation, computation time, and quality of synthesis.
In summary, the proposed representation lends itself for high resolution temporal analysis of non-stationary speech signals, and also allows quality preserving modification and synthesis.
The implementation details of the method are presented in the paper: Time-varying sinusoidal demodulation for non-stationary modeling of speech", in Speech Communication (vol. 105), 2018. The code and some more information is provided in the GitHub repo at click here
| Original signal | |
| Reconstructed signal (after stage-1 IQ) | |
| Reconstructed signal (after stage-2 IQ) | |
| Reconstructed signal (after stage-10 IQ) | |
| Reconstructed voiced stream | |
| Reconstructed unvoiced stream |